
Το Robots.txt είναι ένα από τα απλούστερα αρχεία σε έναν ιστότοπο, αλλά είναι επίσης ένα από τα ευκολότερα να χάσετε. Μόνο ένας χαρακτήρας εκτός τόπου μπορεί να καταστρέψει το SEO σας και να εμποδίσει τις μηχανές αναζήτησης να έχουν πρόσβαση σε σημαντικό περιεχόμενο στον ιστότοπό σας.
Αυτός είναι ο λόγος για τον οποίο οι λανθασμένες διαμορφώσεις του robots.txt είναι εξαιρετικά συχνές, ακόμη και σε έμπειρους επαγγελματίες SEO .
Σε αυτόν τον οδηγό, θα μάθετε:

Τι είναι το αρχείο robots.txt;
Ένα αρχείο robots.txt λέει στις μηχανές αναζήτησης πού μπορούν και δεν μπορούν να πάνε στον ιστότοπό σας.
Καταρχάς, απαριθμεί όλο το περιεχόμενο που θέλετε να κλειδώσετε από μηχανές αναζήτησης όπως το Google. Μπορείτε επίσης να πείτε σε ορισμένες μηχανές αναζήτησης (όχι στο Google) πώς μπορούν να ανιχνεύσουν επιτρεπόμενο περιεχόμενο.
Οι περισσότερες μηχανές αναζήτησης είναι υπάκουες. Δεν έχουν τη συνήθεια να σπάνε μια είσοδο. Τούτου λεχθέντος, ορισμένοι δεν ντρέπονται να διαλέξουν μερικές μεταφορικές κλειδαριές.
Το Google δεν είναι μία από αυτές τις μηχανές αναζήτησης. Τηρούν τις οδηγίες σε ένα αρχείο robots.txt.
Απλώς ξέρετε ότι ορισμένες μηχανές αναζήτησης το αγνοούν εντελώς.
Πώς μοιάζει ένα αρχείο robots.txt;
Ακολουθεί η βασική μορφή ενός αρχείου robots.txt:
Χάρτης ιστοτόπου: [Τοποθεσία διεύθυνσης URL του χάρτη ιστότοπου] Αντιπρόσωπος χρήστη: [αναγνωριστικό bot] [οδηγία 1] [οδηγία 2] [οδηγία ...] Μέλος χρήστη: [άλλο αναγνωριστικό bot] [οδηγία 1] [οδηγία 2] [οδηγία ...]
Εάν δεν έχετε δει ποτέ ένα από αυτά τα αρχεία, αυτό μπορεί να φαίνεται τρομακτικό. Ωστόσο, η σύνταξη είναι αρκετά απλή. Εν ολίγοις, εκχωρείτε κανόνες σε bots δηλώνοντας τον πράκτορα χρήστη που ακολουθείται από οδηγίες .
Ας εξερευνήσουμε αυτά τα δύο συστατικά με περισσότερες λεπτομέρειες.
Χρήστες-πράκτορες
Κάθε μηχανή αναζήτησης ταυτίζεται με διαφορετικό παράγοντα χρήστη. Μπορείτε να ορίσετε προσαρμοσμένες οδηγίες για καθεμία από αυτές στο αρχείο robots.txt. Υπάρχουν εκατοντάδες πράκτορες χρηστών , αλλά εδώ είναι μερικοί χρήσιμοι για το SEO :
Μπορείτε επίσης να χρησιμοποιήσετε το μπαλαντέρ με αστέρι (*) για να εκχωρήσετε οδηγίες σε όλους τους πράκτορες χρήστη.
Για παράδειγμα, ας υποθέσουμε ότι θέλετε να αποκλείσετε την ανίχνευση του ιστότοπού σας εκτός από το Googlebot. Δείτε πώς θα το κάνατε:
Αντιπρόσωπος χρήστη: * Απαγόρευση: / Αντιπρόσωπος χρήστη: Googlebot Να επιτρέπεται: /
Να γνωρίζετε ότι το αρχείο robots.txt μπορεί να περιλαμβάνει οδηγίες για όσους πράκτορες χρηστών θέλετε. Τούτου λεχθέντος, κάθε φορά που δηλώνετε έναν νέο πράκτορα χρήστη, λειτουργεί ως καθαρή πλάκα. Με άλλα λόγια, εάν προσθέσετε οδηγίες για πολλούς πράκτορες χρηστών, οι οδηγίες που δηλώνονται για τον πρώτο πράκτορα χρήστη δεν ισχύουν για το δεύτερο ή τρίτο ή τέταρτο και ούτω καθεξής.
Η εξαίρεση σε αυτόν τον κανόνα είναι όταν δηλώνετε τον ίδιο πράκτορα χρήστη περισσότερες από μία φορές. Σε αυτήν την περίπτωση, όλες οι σχετικές οδηγίες συνδυάζονται και ακολουθούνται.
Τα προγράμματα ανίχνευσης ακολουθούν μόνο τους κανόνες που δηλώνονται στους πράκτορες χρήστη που εφαρμόζονται με μεγαλύτερη ακρίβεια σε αυτούς . Γι 'αυτό το αρχείο robots.txt παραπάνω αποκλείει την ανίχνευση του ιστότοπου εκτός από το Googlebot (και άλλα bot Google). Το Googlebot αγνοεί τη λιγότερο συγκεκριμένη δήλωση παράγοντα χρήστη.
Οδηγίες
Οι οδηγίες είναι κανόνες που θέλετε να ακολουθούν οι δηλωμένοι πράκτορες χρήστη.
Υποστηριζόμενες οδηγίες
Ακολουθούν οδηγίες που υποστηρίζει η Google, μαζί με τις χρήσεις τους.
Απαγορεύω
Χρησιμοποιήστε αυτήν την οδηγία για να δώσετε οδηγίες στις μηχανές αναζήτησης να μην έχουν πρόσβαση σε αρχεία και σελίδες που εμπίπτουν σε συγκεκριμένη διαδρομή. Για παράδειγμα, εάν θέλετε να αποκλείσετε την πρόσβαση όλων των μηχανών αναζήτησης στο ιστολόγιό σας και σε όλες τις αναρτήσεις του, το αρχείο robots.txt μπορεί να μοιάζει με αυτό:
Αντιπρόσωπος χρήστη: * Απαγόρευση: / blog
Επιτρέπω
Χρησιμοποιήστε αυτήν την οδηγία για να επιτρέψετε στις μηχανές αναζήτησης να ανιχνεύουν έναν υποκατάλογο ή μια σελίδα - ακόμη και σε έναν κατάλογο που δεν επιτρέπεται. Για παράδειγμα, εάν θέλετε να αποτρέψετε την πρόσβαση των μηχανών αναζήτησης σε κάθε ανάρτηση στο ιστολόγιό σας εκτός από μία, τότε το αρχείο robots.txt μπορεί να μοιάζει με αυτό:
Αντιπρόσωπος χρήστη: * Απαγόρευση: / blog Να επιτρέπεται: / blog / επιτρεπόμενη ανάρτηση
Σε αυτό το παράδειγμα, οι μηχανές αναζήτησης μπορούν να έχουν πρόσβαση /blog/allowed-post. Αλλά δεν μπορούν να έχουν πρόσβαση:
/blog/another-post/blog/yet-another-post/blog/download-me.pdf
Τόσο η Google όσο και η Bing υποστηρίζουν αυτήν την οδηγία.
Εάν δεν είστε προσεκτικοί, απαγορεύστε και επιτρέψτε τις οδηγίες μπορούν εύκολα να έρχονται σε σύγκρουση μεταξύ τους. Στο παρακάτω παράδειγμα, απαγορεύουμε την πρόσβαση /blog/ και την πρόσβαση /blog.
Αντιπρόσωπος χρήστη: * Απαγόρευση: / blog / Να επιτρέπεται: / blog
Σε αυτήν την περίπτωση, η διεύθυνση URL /blog/post-title/ φαίνεται να μην επιτρέπεται ούτε να επιτρέπεται. Λοιπόν, τι κερδίζει;
Για το Google και το Bing, ο κανόνας είναι ότι κερδίζει η οδηγία με τους περισσότερους χαρακτήρες. Εδώ, αυτή είναι η απαγόρευση της οδηγίας.
Disallow: /blog/ (6 χαρακτήρες)Allow: /blog (5 χαρακτήρες)
Εάν οι οδηγίες αδειοδότησης και απαγόρευσης έχουν το ίδιο μήκος, κερδίζει η λιγότερο περιοριστική οδηγία. Σε αυτήν την περίπτωση, αυτή θα ήταν η οδηγία περί αδειών.
Βασικά, αυτό ισχύει μόνο για το Google και το Bing . Άλλες μηχανές αναζήτησης ακούνε την πρώτη οδηγία αντιστοίχισης. Σε αυτήν την περίπτωση, αυτό δεν επιτρέπεται.
Χάρτης ιστοτόπου
Χρησιμοποιήστε αυτήν την οδηγία για να καθορίσετε τη θέση του χάρτη ιστοτόπου σας στις μηχανές αναζήτησης. Εάν δεν είστε εξοικειωμένοι με τους χάρτες ιστότοπου, συνήθως περιλαμβάνουν τις σελίδες που θέλετε να ανιχνεύσουν και να ευρετηριάσουν οι μηχανές αναζήτησης.
Ακολουθεί ένα παράδειγμα αρχείου robots.txt χρησιμοποιώντας την οδηγία χάρτη ιστότοπου:
Χάρτης ιστοτόπου: https://www.domain.com/sitemap.xml Αντιπρόσωπος χρήστη: * Απαγόρευση: / blog / Να επιτρέπεται: / blog / post-title /
Πόσο σημαντικό είναι να συμπεριλάβετε τους χάρτες ιστοτόπου σας στο αρχείο robots.txt; Εάν έχετε ήδη υποβάλει μέσω του Search Console, τότε είναι κάπως περιττό για το Google. Ωστόσο, λέει σε άλλες μηχανές αναζήτησης όπως το Bing πού να βρει τον χάρτη ιστότοπού σας, οπότε εξακολουθεί να είναι καλή πρακτική.
Λάβετε υπόψη ότι δεν χρειάζεται να επαναλάβετε την οδηγία χάρτη ιστότοπου πολλές φορές για κάθε πράκτορα χρήστη. Δεν ισχύει μόνο για ένα. Επομένως, καλύτερα να συμπεριλάβετε οδηγίες χάρτη ιστότοπου στην αρχή ή στο τέλος του αρχείου robots.txt. Για παράδειγμα:
Χάρτης ιστοτόπου: https://www.domain.com/sitemap.xml Αντιπρόσωπος χρήστη: Googlebot Απαγόρευση: / blog / Να επιτρέπεται: / blog / post-title / Χρήστης-πράκτορας: Bingbot Απαγόρευση: / υπηρεσίες /
Η Google υποστηρίζει την οδηγία για το χάρτη ιστότοπων , όπως και οι Ask, Bing και Yahoo.
Μη υποστηριζόμενες οδηγίες
Ακολουθούν οι οδηγίες που δεν υποστηρίζονται πλέον από την Google - μερικές από τις οποίες τεχνικά δεν ήταν ποτέ.
Καθυστέρηση ανίχνευσης
Προηγουμένως, θα μπορούσατε να χρησιμοποιήσετε αυτήν την οδηγία για να καθορίσετε μια καθυστέρηση ανίχνευσης σε δευτερόλεπτα. Για παράδειγμα, εάν θέλετε το Googlebot να περιμένει 5 δευτερόλεπτα μετά από κάθε ενέργεια ανίχνευσης, θα έχετε ορίσει την καθυστέρηση ανίχνευσης σε 5 όπως:
Αντιπρόσωπος χρήστη: Googlebot Καθυστέρηση ανίχνευσης: 5
Η Google δεν υποστηρίζει πλέον αυτήν την οδηγία, αλλά οι Bing και Yandex το κάνουν.
Τούτου λεχθέντος, προσέξτε κατά τη θέσπιση αυτής της οδηγίας, ειδικά εάν έχετε έναν μεγάλο ιστότοπο. Εάν ορίσετε καθυστέρηση ανίχνευσης 5 δευτερολέπτων, τότε περιορίζετε τα bots στην ανίχνευση έως 17.280 διευθύνσεων URL την ημέρα. Αυτό δεν είναι πολύ χρήσιμο αν έχετε εκατομμύρια σελίδες, αλλά θα μπορούσε να εξοικονομήσει εύρος ζώνης εάν έχετε έναν μικρό ιστότοπο.
Noindex
Αυτή η οδηγία δεν υποστηρίχθηκε ποτέ επίσημα από την Google. Ωστόσο, μέχρι πρόσφατα, πιστεύεται ότι η Google είχε κάποιον «κώδικα που χειρίζεται μη υποστηριζόμενους και μη δημοσιευμένους κανόνες (όπως το noindex)». Επομένως, εάν θέλετε να αποτρέψετε το Google από το ευρετήριο όλων των δημοσιεύσεων στο ιστολόγιό σας, θα μπορούσατε να χρησιμοποιήσετε την ακόλουθη οδηγία:
Αντιπρόσωπος χρήστη: Googlebot Noindex: / blog /
Ωστόσο, την 1η Σεπτεμβρίου 2019, η Google κατέστησε σαφές ότι αυτή η οδηγία δεν υποστηρίζεται . Αν θέλετε να εξαιρέσετε μια σελίδα ή ένα αρχείο από τις μηχανές αναζήτησης, χρησιμοποιήστε την ετικέτα μετα-ρομπότ ή την κεφαλίδα HTTP x-robots .
Nofollow
Αυτή είναι μια άλλη οδηγία που η Google δεν υποστήριξε ποτέ επίσημα και χρησιμοποιήθηκε για να δώσει οδηγίες στις μηχανές αναζήτησης να μην ακολουθούν συνδέσμους σε σελίδες και αρχεία σε συγκεκριμένη διαδρομή. Για παράδειγμα, εάν θέλετε να εμποδίσετε την Google να ακολουθεί όλους τους συνδέσμους στο ιστολόγιό σας, μπορείτε να χρησιμοποιήσετε την ακόλουθη οδηγία:
Αντιπρόσωπος χρήστη: Googlebot Nofollow: / blog /
Η Google ανακοίνωσε ότι αυτή η οδηγία δεν υποστηρίζεται επισήμως την 1η Σεπτεμβρίου 2019. Εάν θέλετε να αφαιρέσετε όλους τους συνδέσμους σε μια σελίδα τώρα, θα πρέπει να χρησιμοποιήσετε τη μετα-ετικέτα ρομπότ ή την κεφαλίδα x-robots. Αν θέλετε να πείτε στην Google να μην ακολουθεί συγκεκριμένους συνδέσμους σε μια σελίδα, χρησιμοποιήστε το χαρακτηριστικό συνδέσμου rel = “nofollow”.
Χρειάζεστε ένα αρχείο robots.txt;
Το να έχετε ένα αρχείο robots.txt δεν είναι κρίσιμο για πολλούς ιστότοπους, ειδικά για μικρούς.
Τούτου λεχθέντος, δεν υπάρχει κανένας καλός λόγος να μην έχουμε έναν. Σας δίνει περισσότερο έλεγχο για το πού μπορούν και δεν μπορούν να πάνε οι μηχανές αναζήτησης στον ιστότοπό σας και αυτό μπορεί να βοηθήσει με πράγματα όπως:
Σημειώστε ότι ενώ η Google δεν συνήθως ευρετήριο των ιστοσελίδων που έχουν αποκλειστεί στο robots.txt, δεν υπάρχει κανένας τρόπος να εγγυηθεί τον αποκλεισμό από τα αποτελέσματα αναζήτησης χρησιμοποιώντας το αρχείο robots.txt .
Όπως λέει η Google , εάν το περιεχόμενο συνδέεται με άλλα μέρη στον Ιστό, ενδέχεται να εξακολουθεί να εμφανίζεται στα αποτελέσματα αναζήτησης Google.
Πώς να βρείτε το αρχείο robots.txt
Εάν έχετε ήδη ένα αρχείο robots.txt στον ιστότοπό σας, θα είναι προσβάσιμο στη διεύθυνση domain.com/robots.txt . Μεταβείτε στη διεύθυνση URL του προγράμματος περιήγησής σας. Εάν δείτε κάτι τέτοιο, τότε έχετε ένα αρχείο robots.txt:

Πώς να δημιουργήσετε ένα αρχείο robots.txt
Εάν δεν έχετε ήδη αρχείο robots.txt, η δημιουργία ενός είναι εύκολη. Απλώς ανοίξτε ένα κενό έγγραφο .txt και αρχίστε να πληκτρολογείτε οδηγίες. Για παράδειγμα, εάν θέλετε να απαγορεύσετε σε όλες τις μηχανές αναζήτησης να ανιχνεύουν τον /admin/κατάλογό σας , θα μοιάζει με αυτό:
Αντιπρόσωπος χρήστη: * Απαγόρευση: / admin /
Συνεχίστε να δημιουργείτε τις οδηγίες μέχρι να είστε ικανοποιημένοι με αυτό που έχετε. Αποθηκεύστε το αρχείο σας ως "robots.txt".
Εναλλακτικά, μπορείτε επίσης να χρησιμοποιήσετε μια γεννήτρια robots.txt όπως αυτή .
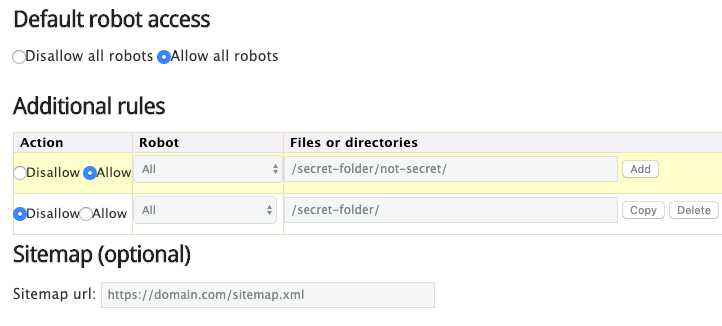
Το πλεονέκτημα της χρήσης ενός τέτοιου εργαλείου είναι ότι ελαχιστοποιεί τα σφάλματα σύνταξης. Αυτό είναι καλό, διότι ένα λάθος θα μπορούσε να οδηγήσει σε καταστροφή SEO για τον ιστότοπό σας - γι 'αυτό πρέπει να προσέξετε.
Το μειονέκτημα είναι ότι είναι κάπως περιορισμένοι όσον αφορά την προσαρμοστικότητα.
Πού να τοποθετήσετε το αρχείο robots.txt
Τοποθετήστε το αρχείο robots.txt στον ριζικό κατάλογο του υποτομέα στον οποίο εφαρμόζεται. Για παράδειγμα, για τον έλεγχο της συμπεριφοράς ανίχνευσης στο domain.com , το αρχείο robots.txt θα πρέπει να είναι προσβάσιμο στη διεύθυνση domain.com/robots.txt .
Εάν θέλετε να ελέγξετε την ανίχνευση σε έναν υποτομέα όπως το blog.domain.com , τότε το αρχείο robots.txt θα πρέπει να είναι προσβάσιμο στη διεύθυνση blog.domain.com/robots.txt .
Βέλτιστες πρακτικές αρχείων Robots.txt
Έχετε υπόψη σας για να αποφύγετε κοινά λάθη.
Χρησιμοποιήστε μια νέα γραμμή για κάθε οδηγία
Κάθε οδηγία πρέπει να βρίσκεται σε μια νέα γραμμή. Διαφορετικά, θα προκαλέσει σύγχυση στις μηχανές αναζήτησης.
Κακό:
User-agent: * Disallow: / directory / Disallow: / another-κατάλογος /
Καλός:
Αντιπρόσωπος χρήστη: * Απαγόρευση: / κατάλογος / Απαγόρευση: / άλλος-κατάλογος /
Χρησιμοποιήστε μπαλαντέρ για απλοποίηση των οδηγιών
Όχι μόνο μπορείτε να χρησιμοποιήσετε χαρακτήρες μπαλαντέρ (*) για την εφαρμογή οδηγιών σε όλους τους πράκτορες χρήστη, αλλά και για την αντιστοίχιση μοτίβων διευθύνσεων URL κατά τη δήλωση οδηγιών. Για παράδειγμα, εάν θέλετε να αποτρέψετε την πρόσβαση των μηχανών αναζήτησης σε παραμέτρους διευθύνσεων URL κατηγορίας προϊόντων στον ιστότοπό σας, μπορείτε να τις αναφέρετε ως εξής:
Αντιπρόσωπος χρήστη: * Απαγόρευση: / προϊόντα / μπλουζάκια; Απαγόρευση: / products / hoodies; Να μην επιτρέπονται: / προϊόντα / μπουφάν; …
Αλλά αυτό δεν είναι πολύ αποτελεσματικό. Θα ήταν καλύτερα να απλοποιήσετε τα πράγματα με ένα μπαλαντέρ όπως αυτό:
Αντιπρόσωπος χρήστη: * Να μην επιτρέπεται: / products / *;
Αυτό το παράδειγμα εμποδίζει τις μηχανές αναζήτησης να ανιχνεύουν όλες τις διευθύνσεις URL κάτω από το / product / subfolder που περιέχουν ερωτηματικό. Με άλλα λόγια, οποιεσδήποτε παραμετροποιημένες διευθύνσεις URL κατηγορίας προϊόντων.
Χρησιμοποιήστε το "$" για να καθορίσετε το τέλος μιας διεύθυνσης URL
Συμπεριλάβετε το σύμβολο "$" για να επισημάνετε το τέλος μιας διεύθυνσης URL . Για παράδειγμα, εάν θέλετε να αποτρέψετε την πρόσβαση των μηχανών αναζήτησης σε όλα τα αρχεία .pdf στον ιστότοπό σας, το αρχείο robots.txt μπορεί να μοιάζει με αυτό:
Αντιπρόσωπος χρήστη: * Απαγόρευση: /*.pdf$
Σε αυτό το παράδειγμα, οι μηχανές αναζήτησης δεν μπορούν να έχουν πρόσβαση σε διευθύνσεις URL που τελειώνουν με .pdf. Αυτό σημαίνει ότι δεν έχουν πρόσβαση στο /file.pdf, αλλά μπορούν να έχουν πρόσβαση στο /file.pdf?id=68937586 επειδή αυτό δεν τελειώνει με το ".pdf".
Χρησιμοποιήστε κάθε παράγοντα χρήστη μόνο μία φορά
Εάν καθορίσετε τον ίδιο πράκτορα χρήστη πολλές φορές, η Google δεν πειράζει. Θα συνδυάζει απλώς όλους τους κανόνες από τις διάφορες δηλώσεις σε έναν και θα τους ακολουθεί όλους. Για παράδειγμα, εάν είχατε τους ακόλουθους πράκτορες χρήστη και οδηγίες στο αρχείο robots.txt…
Αντιπρόσωπος χρήστη: Googlebot Απαγόρευση: / a / Αντιπρόσωπος χρήστη: Googlebot Απαγόρευση: / b /
… Το Googlebot δεν θα ανιχνεύσει κανέναν από αυτούς τους υποφακέλους.
Τούτου λεχθέντος, είναι λογικό να δηλώνεται κάθε πράκτορας χρήστη μόνο μία φορά επειδή είναι λιγότερο σύγχυση. Με άλλα λόγια, είναι λιγότερο πιθανό να κάνετε κρίσιμα λάθη διατηρώντας τα πράγματα τακτοποιημένα και απλά.
Χρησιμοποιήστε ειδικότητα για να αποφύγετε ακούσια λάθη
Η μη παροχή συγκεκριμένων οδηγιών κατά τον καθορισμό οδηγιών μπορεί να οδηγήσει σε λάθη που χάνονται εύκολα και μπορεί να έχουν καταστροφικές επιπτώσεις στο SEO σας . Για παράδειγμα, ας υποθέσουμε ότι διαθέτετε έναν πολύγλωσσο ιστότοπο και εργάζεστε σε μια γερμανική έκδοση που θα είναι διαθέσιμη στον / de / υποκατάλογο.
Επειδή δεν είναι αρκετά έτοιμο, θέλετε να αποτρέψετε την πρόσβαση σε μηχανές αναζήτησης.
Το παρακάτω αρχείο robots.txt θα αποτρέψει την πρόσβαση των μηχανών αναζήτησης σε αυτόν τον υποφάκελο και σε όλα:
Αντιπρόσωπος χρήστη: * Απαγόρευση: / de
Αλλά θα αποτρέψει επίσης τις μηχανές αναζήτησης από την ανίχνευση οποιωνδήποτε σελίδων ή αρχείων που ξεκινούν από /de.
Για παράδειγμα:
/designer-dresses//delivery-information.html/depeche-mode/t-shirts//definitely-not-for-public-viewing.pdf
Σε αυτήν την περίπτωση, η λύση είναι απλή: προσθέστε ένα τελείωμα.
Αντιπρόσωπος χρήστη: * Απαγόρευση: / de /
Χρησιμοποιήστε σχόλια για να εξηγήσετε το αρχείο robots.txt στους ανθρώπους
Τα σχόλια βοηθούν στην εξήγηση του αρχείου robots.txt σε προγραμματιστές - και ενδεχομένως ακόμη και στον μελλοντικό εαυτό σας Για να συμπεριλάβετε ένα σχόλιο, ξεκινήστε τη γραμμή με ένα hash (#).
# Αυτό δίνει εντολή στο Bing να μην ανιχνεύσει τον ιστότοπό μας. Χρήστης-πράκτορας: Bingbot Απαγόρευση: /
Τα προγράμματα ανίχνευσης θα αγνοήσουν τα πάντα σε γραμμές που ξεκινούν με κατακερματισμό.
Χρησιμοποιήστε ένα ξεχωριστό αρχείο robots.txt για κάθε υποτομέα
Το Robots.txt ελέγχει μόνο τη συμπεριφορά ανίχνευσης στον υποτομέα όπου φιλοξενείται. Εάν θέλετε να ελέγξετε την ανίχνευση σε διαφορετικό υποτομέα, θα χρειαστείτε ένα ξεχωριστό αρχείο robots.txt.
Για παράδειγμα, εάν ο κύριος ιστότοπός σας βρίσκεται στο domain.com και το ιστολόγιό σας βρίσκεται στο blog.domain.com , τότε θα χρειαστείτε δύο αρχεία robots.txt. Το ένα πρέπει να πάει στον ριζικό κατάλογο του κύριου τομέα και το άλλο στον ριζικό κατάλογο του ιστολογίου.
Παράδειγμα αρχείων robots.txt
Ακολουθούν μερικά παραδείγματα αρχείων robots.txt. Αυτά είναι κυρίως για έμπνευση, αλλά εάν συμβεί κάτι που ταιριάζει με τις απαιτήσεις σας, αντιγράψτε το σε ένα κείμενο, αποθηκεύστε το ως "robots.txt" και ανεβάστε το στον κατάλληλο κατάλογο.
All-Access για όλα τα bots
Αντιπρόσωπος χρήστη: * Απαγορεύω:
Δεν υπάρχει πρόσβαση για όλα τα bots
Αντιπρόσωπος χρήστη: * Απαγόρευση: /
Αποκλεισμός ενός υποκαταλόγου για όλα τα bots
Αντιπρόσωπος χρήστη: * Απαγόρευση: / φάκελος /
Αποκλεισμός ενός υποκαταλόγου για όλα τα bots (επιτρέπεται ένα αρχείο εντός)
Αντιπρόσωπος χρήστη: * Απαγόρευση: / φάκελος / Να επιτρέπεται: /folder/page.html
Αποκλεισμός ενός αρχείου για όλα τα bots
Αντιπρόσωπος χρήστη: * Απαγόρευση: /this-is-a-file.pdf
Αποκλεισμός ενός τύπου αρχείου ( PDF ) για όλα τα bots
Αντιπρόσωπος χρήστη: * Απαγόρευση: /*.pdf$
Αποκλεισμός όλων των παραμετροποιημένων διευθύνσεων URL μόνο για το Googlebot
Αντιπρόσωπος χρήστη: Googlebot Να μην επιτρέπεται: / *;
Πώς να ελέγξετε το αρχείο robots.txt για σφάλματα
Τα λάθη του Robots.txt μπορούν να περάσουν εύκολα από το δίχτυ, οπότε είναι χρήσιμο να παρακολουθείτε τα προβλήματα.
Για να το κάνετε αυτό, ελέγχετε τακτικά ζητήματα που σχετίζονται με το robots.txt στην αναφορά "Κάλυψη" στο Search Console . Ακολουθούν μερικά από τα σφάλματα που μπορεί να δείτε, τι σημαίνουν και πώς μπορείτε να τα διορθώσετε.
Επικολλήστε μια διεύθυνση URL στο εργαλείο επιθεώρησης διευθύνσεων URL της Google στο Search Console. Εάν έχει αποκλειστεί από το robots.txt, θα πρέπει να δείτε κάτι τέτοιο:
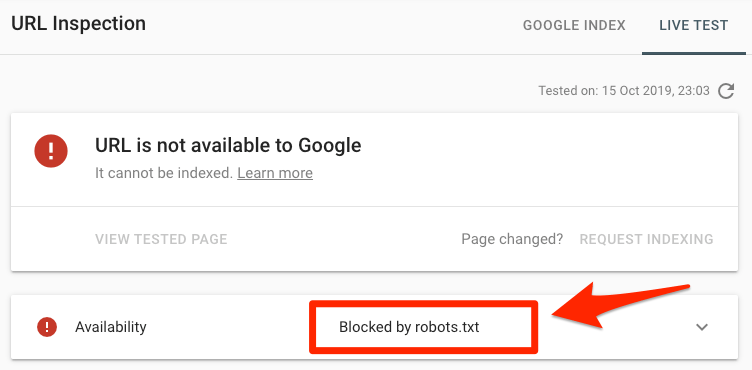
Η διεύθυνση URL που υποβλήθηκε αποκλείστηκε από το robots.txt
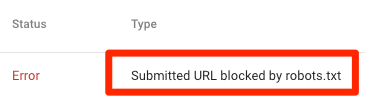
Αυτό σημαίνει ότι τουλάχιστον ένα από τα URL στους χάρτες ιστοτόπου που έχετε υποβάλει αποκλείεται από το robots.txt.
Εάν δημιουργήσατε σωστά το χάρτη ιστότοπού σας και εξαιρέσατε τις κανονικοποιημένες , τις μη καταχωρημένες και τις ανακατευθυνόμενες σελίδες, τότε καμία υποβαλλόμενη σελίδα δεν θα πρέπει να αποκλειστεί από το robots.txt . Εάν είναι, διερευνήστε ποιες σελίδες επηρεάζονται και, στη συνέχεια, προσαρμόστε το αρχείο robots.txt ανάλογα για να καταργήσετε το μπλοκ για αυτήν τη σελίδα.
Μπορείτε να χρησιμοποιήσετε τον ελεγκτή robots.txt της Google για να δείτε ποια οδηγία αποκλείει το περιεχόμενο. Απλά προσέξτε όταν το κάνετε αυτό. Είναι εύκολο να κάνετε λάθη που επηρεάζουν άλλες σελίδες και αρχεία.
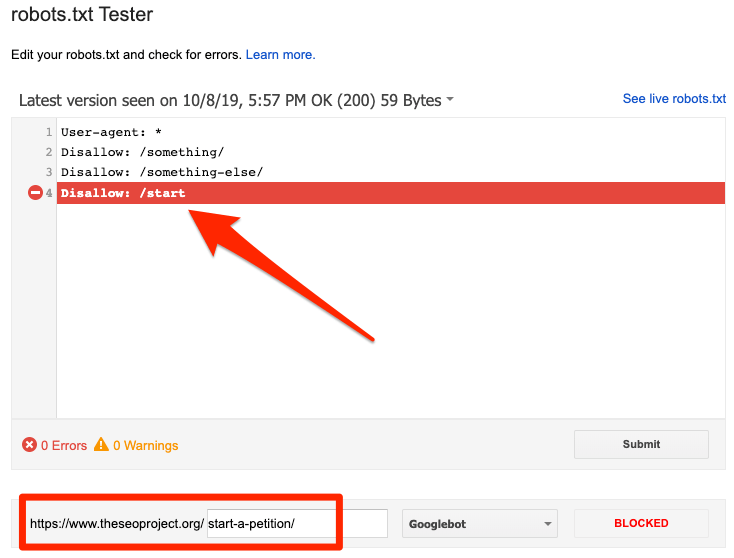
Αποκλείστηκε από το robots.txt
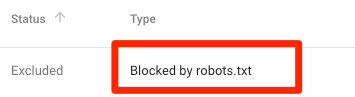
Αυτό σημαίνει ότι έχετε αποκλείσει περιεχόμενο από το robots.txt που δεν έχει ευρετηριαστεί στο Google αυτήν τη στιγμή.
Εάν αυτό το περιεχόμενο είναι σημαντικό και πρέπει να ευρετηριαστεί, καταργήστε το μπλοκ ανίχνευσης στο robots.txt. (Αξίζει επίσης να βεβαιωθείτε ότι το περιεχόμενο δεν είναι απαρχαιωμένο). Εάν έχετε αποκλείσει περιεχόμενο στο robots.txt με σκοπό να το εξαιρέσετε από το ευρετήριο της Google, καταργήστε το μπλοκ ανίχνευσης και χρησιμοποιήστε μια μετα-ετικέτα ρομπότ ή x-robots-header. Αυτός είναι ο μόνος τρόπος για να διασφαλιστεί ο αποκλεισμός περιεχομένου από το ευρετήριο της Google.
Ευρετηρίαση, αν και αποκλείστηκε από το robots.txt
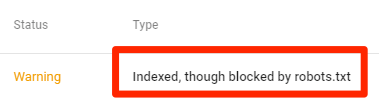
Αυτό σημαίνει ότι μέρος του περιεχομένου που αποκλείεται από το robots.txt εξακολουθεί να ευρετηριάζεται στο Google.
Για άλλη μια φορά, εάν προσπαθείτε να εξαιρέσετε αυτό το περιεχόμενο από τα αποτελέσματα αναζήτησης της Google, το robots.txt δεν είναι η σωστή λύση. Καταργήστε το μπλοκ ανίχνευσης και αντ 'αυτού χρησιμοποιήστε μια ετικέτα μετα-ρομπότ ή μια κεφαλίδα HTTP x-robots-tag για να αποτρέψετε την ευρετηρίαση.
Εάν αποκλείσατε τυχαία αυτό το περιεχόμενο και θέλετε να το διατηρήσετε στο ευρετήριο της Google, καταργήστε το μπλοκ ανίχνευσης στο robots.txt. Αυτό μπορεί να βοηθήσει στη βελτίωση της προβολής του περιεχομένου στην αναζήτηση Google.
Συνιστώμενη ανάγνωση: Πώς να διορθώσετε το "ευρετήριο, αν και αποκλείστηκε από το robots.txt" στο GSC
Συχνές ερωτήσεις
Ακολουθούν μερικές συνήθεις ερωτήσεις που δεν ταιριάζουν φυσικά αλλού στον οδηγό μας. Ενημερώστε μας στα σχόλια εάν λείπει κάτι και θα ενημερώσουμε αναλόγως την ενότητα.
Ποιο είναι το μέγιστο μέγεθος ενός αρχείου robots.txt;
500 kilobytes (περίπου).
Πού είναι το robots.txt στο WordPress;
Ίδιο μέρος: domain.com/robots.txt .
Πώς μπορώ να επεξεργαστώ το robots.txt στο WordPress;
Είτε με το χέρι είτε χρησιμοποιώντας ένα από τα πολλά πρόσθετα WordPress SEO όπως το Yoast που σας επιτρέπουν να επεξεργαστείτε το robots.txt από το backend του WordPress.
Τι θα συμβεί αν δεν επιτρέψω την πρόσβαση σε περιεχόμενο που δεν ανήκει στο robots.txt;
Η Google δεν θα δει ποτέ την οδηγία noindex επειδή δεν μπορεί να ανιχνεύσει τη σελίδα.
Τελικές σκέψεις
Το Robots.txt είναι ένα απλό αλλά ισχυρό αρχείο. Χρησιμοποιήστε το με σύνεση και μπορεί να έχει θετικό αντίκτυπο στο SEO . Χρησιμοποιήστε το τυχαία και, καλά, θα ζήσετε να το μετανιώσετε.



0 Σχόλια